La programación reactiva supone un revolucionario paradigma basado en el consumo constante de información siendo la clave la implementación del viejo conocido patrón observador, pero en vez de para los eventos, para todos los elementos. Estamos hablando por lo tanto de un modelo de publicación/suscripción constituido por flujos de datos asíncronos suscritos que obtienen la información en tiempo real con la posibilidad de cuantizar la misma, indicando la cantidad de datos que se quiere recibir y en consecuencia minimizando la latencia y evitando los bloqueos.
El origen de la programación reactiva nace con el Manifiesto reactivo que indica que un sistema reactivo debe ser: Responsivo, resilente, elástico y orientado a mensajes.
La motivación originaria de ésta corriente pretende resolver problemáticas actuales como son el desaprovechamiento del uso de la CPU debido al I/O, el sobreuso de memoria y la ineficiencia de las interacciones bloqueantes.
De entre los casos de éxito cabe destacar a Netflix como compañia con una amplia madurez en el uso de programción reactiva para la mejora del rendimiento de sus aplicaciones y orquestación de sus microservicios.
Pese a la poca longevidad existe una evolución de la programación reactiva y en este artículo vamos a centrarnos en el API más actual (Poject Reactor), evolución de RxJava2 y contenido en el core de Spring 5.
La piedra angular de la programación reactiva de última greneración son las clases Flux y Mono implementadoras ámbas de la interfaz Publisher.
A modo de ejemplo vamos a analizar un microservicio Spring 5 , Spring-boot 2 con MonogoDB reactive donde profundizaremos en los fundamentos y diferentes opciones de creación y uso de flujos.
Teneis disponible el código en mi cuenta de github.
La tecnología utilizada es Spring 5 que trae de seríe el módulo reactor-core, spring-boot 2, MongoDB reactive y Java 8 . El objetivo es centrar el foco en la parte Reactive dando por hecho que el lector tiene conocimientos de Spring 5 y Spring-boot.
Os muestro las dependencias del pom.xml
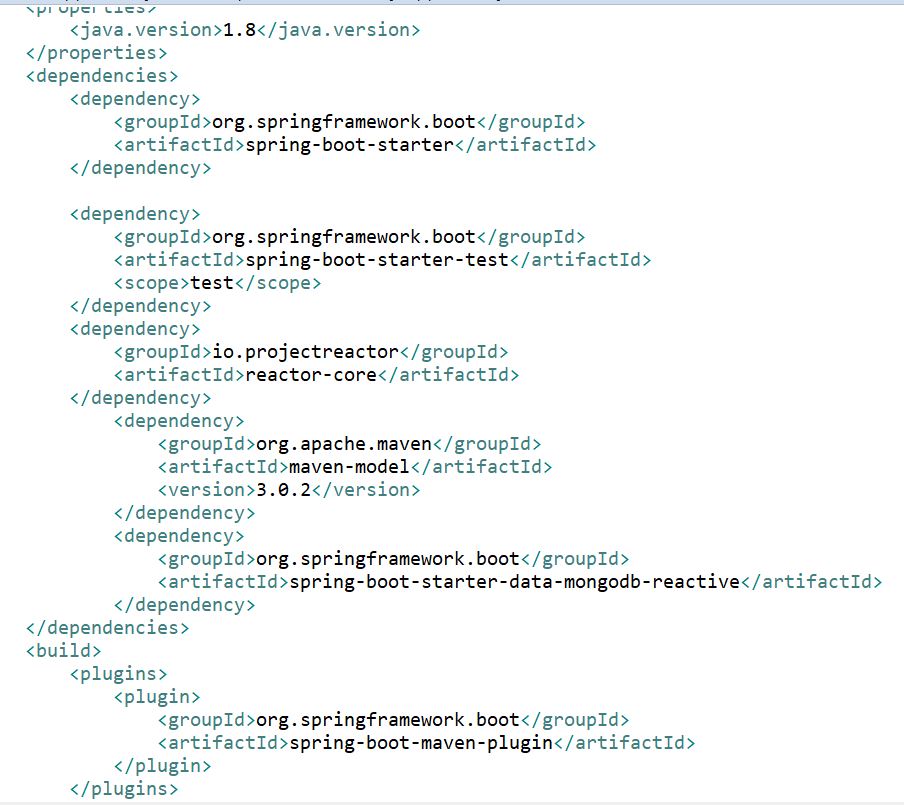
Comentar que aunque Project Reactor comienza a estar disponible con la JDK 9, Spring 5 si permite usar la versión 8 al tener en su core todo lo necesario.
Vamos a ver los modos de crear flujos , como transformarlos , como fusionarlos y como suscribirlos.
Como ya comentamos previamente tenemos dos clases que implementan la interfaz Publisher, Flux y Mono. la difrencia principal es que la última solo contiene un elemento a diferencia de Flux que contiene un conjunto de elementos finito o infinito.
Existen varias maneras de generar flujos asíncronos, vamos a ver los más importantes.
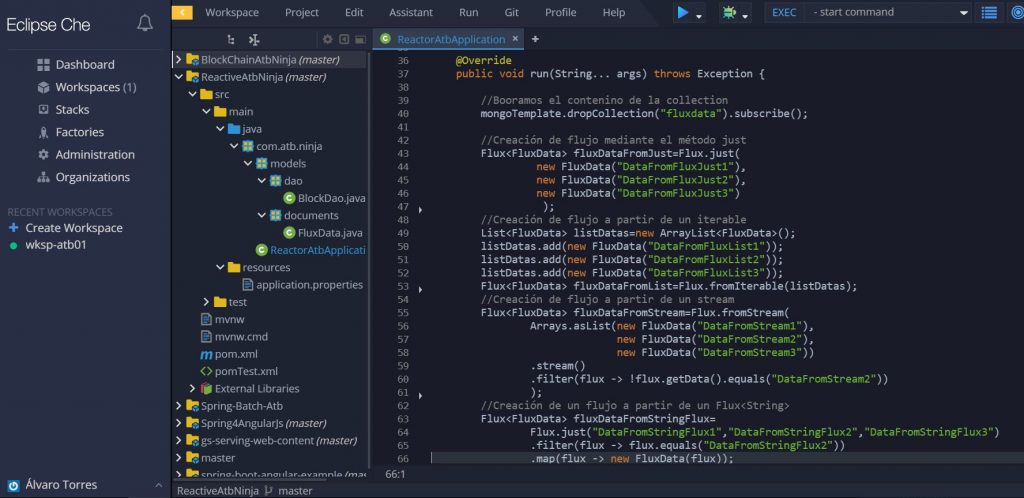
- Mediante el método just . Como se muestra en la captura se incluyen los constuctores de los objetos del Flux separados por coma. En nuestro caso serán del tipo FluxData (que es el bean sincronizado con la collection de MogonDB fluxdata que es donde vamos a persistir la información.
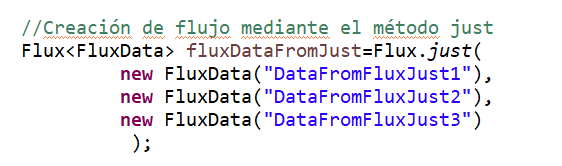
- A partir de un iterable. Para cualquier clase que herede de Iterable como List,Map,Set…… se dispone del método fromIterable
- A partir de un Stream el flujo puede crearse mediante el método fromStream
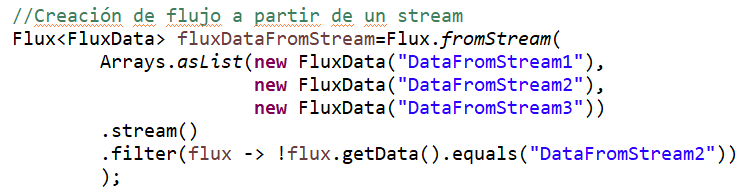
- Como transformación de un flujo de otro tipo. En éste caso partimos de un Flux<String> y con una transformación lambda mediante map lo convertimos en Flux<FluxData> .
En éste útimo modo de creación de un flujo lo que realmente se realiza es una transformación de tipo map similar a la que se realiza posteriormente a la hora de persistir, precisamente para transformar un Flux<FluxData> en Mono<FluxData>

Es importante matizar que en este caso es necesario usar flatMap en vez de map ya que lo que se va a realizar es insertar de cada FluxData en la collection siendo cada operación del tipo Mono<FluxData> El funcionamiento de map y flatMap con Flux es completamente equivalente al funcionamiento con Stream y no por casualidad.
Otras opciones de transformación son el filtrado (filter) y la ordenación (sort). Podemos observar como se está omitiendo «DataFromStream2» del flujo originario de Stream , en el caso del flujo originario de Flux<String> solo se está seleccionando «DataFromStringFlux2» y en el flujo unificado se omiten las que finalizan en «1». Por otro lado se está realizando una ordenanción natural por el atributo data.
A partir de todos los flujos descritos realizamos una unificación de los mismos mediante merge.

La clase Flux presenta diferentes opciones de merge siendo concat otra opción de unificación de flujos útil.
Pues bien tenemos un flujo unificado que parte de varios flujos que han sido transformados..en este punto es necesario realizar una suscripción

Tenemos disponible el método subscribe que no tiene porque tener asociada ninguna implemntación funcional pero que en nuestro caso hemos implementado trazando en el log info el flujo , el mensaje de la excepción en el log de error en caso de producirse y un Runnable() donde simplemente realizamos un trazado en log info del final del proceso satisfactoriamente pero donde podría realizarse una implementación más compleja.
Si consultamos en MogoDB Reactive vemos que la collection está compuesta por los siguientes elementos.
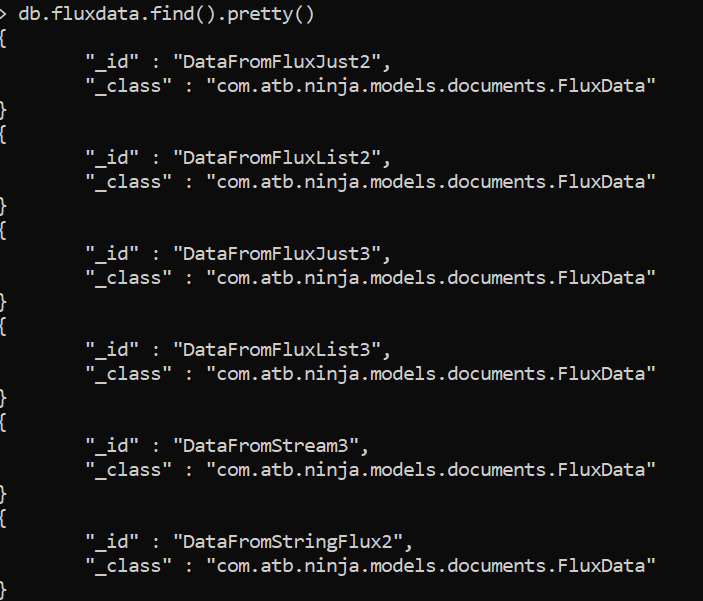
Comprobamos que el resultado es correcto, ya que se han excluido todos los elementos que finalizan en 1 , para el procedente de Stream solo se muestra «DataFromStream3″ ya que se excluyó «DataFromStream2″, solo se muestra «DataFromStringFlux2″ como se indicó en su filtrado y en cuanto a los elementos provenientes de Just y de List vemos que la collection los ha guardado en el siguiente orden «DataFromFluxJust2″, «DataFromFluxList2», «DataFromFluxJust3», «DataFromFluxList2» eso es debido precisamente a que el flujo resultante del merge se encuentra ordenado de manera natural y precisamente y a diferencia de la programación no reactiva en la que aparecerian primero los del flujo Just y a continuación los del flujo List lo que observamos es la disponibilidad temporal en paralelo de ambos flujos con su correspondiente eficiencia en rendimiento…que obviamente en el ejemplo no se aprecia debido al bajo volumen de información pero que si que podemos poner de maniefiesto.